TL;DR: I combined dlt, dbt, DuckDB, MotherDuck, and Metabase to create a Modern Data Stack in a box that makes it very easy to create a data pipeline from scratch and then deploy it to production.
I started working in dltHub in March 2023, right around the time when we released DuckDB as a destination for dlt. As a Python user, being able to create a data pipeline, load the data in my laptop, and explore and query the data all in python was awesome.
At the time I also came across this very cool article by Jacob Matson in which he talks about creating a Modern Data Stack(MDS) in a box with DuckDB. I was already fascinated with dlt and all the other new tools that I was discovering, so reading about this approach of combining different tools to execute an end-to-end proof of concept in your laptop was especially interesting.
Fast forward to a few weeks ago when dlt released MotherDuck as a destination. The first thing that I thought of was an approach to MDS in a box where you develop locally with DuckDB and deploy in the cloud with MotherDuck. I wanted to try it out.
What makes this awesome
In my example, I wanted to customize reports on top of Google Analytics 4 (GA4) and combine it with data from GitHub. This is usually challenging because, while exporting data from GA4 to BigQuery is simple, combining it with other sources and creating custom analytics on top of it can get pretty complicated.
By first pulling all the data from different sources into DuckDB files in my laptop, I was able to do my development and customization locally.
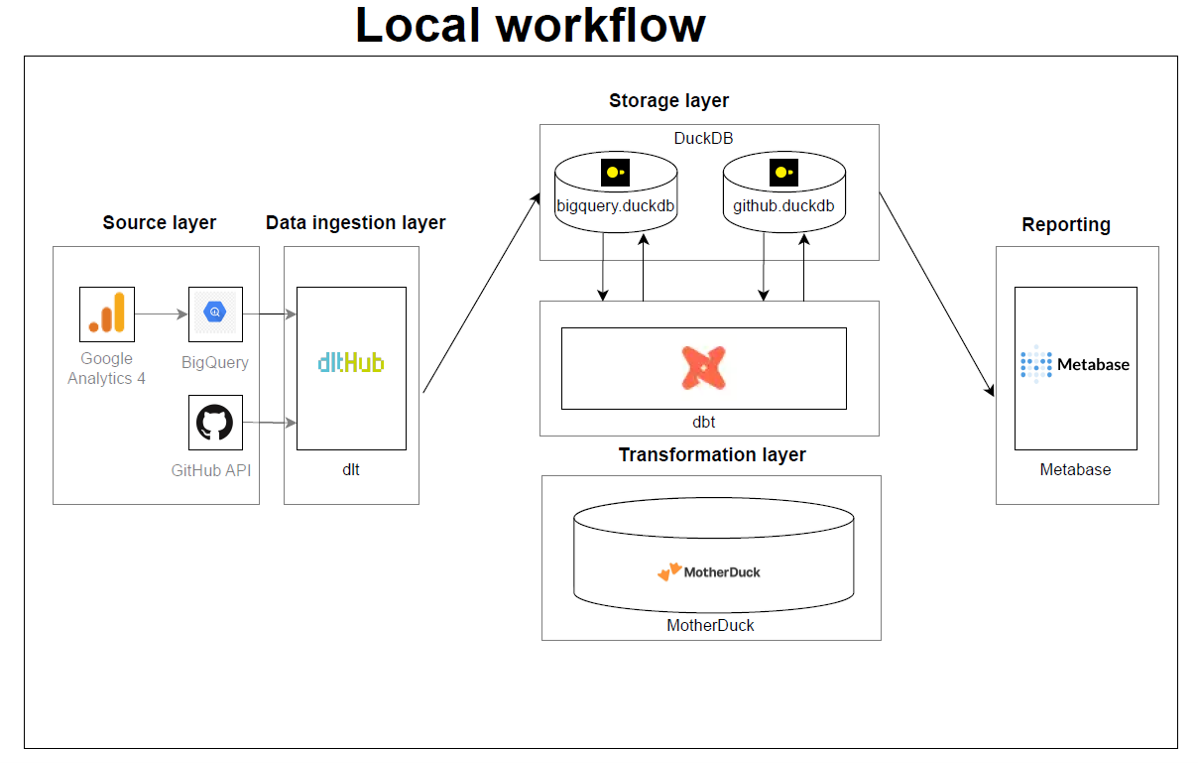
And then when I was ready to move to production, I was able to seamlessly switch from DuckDB to MotherDuck with almost no code re-writing!
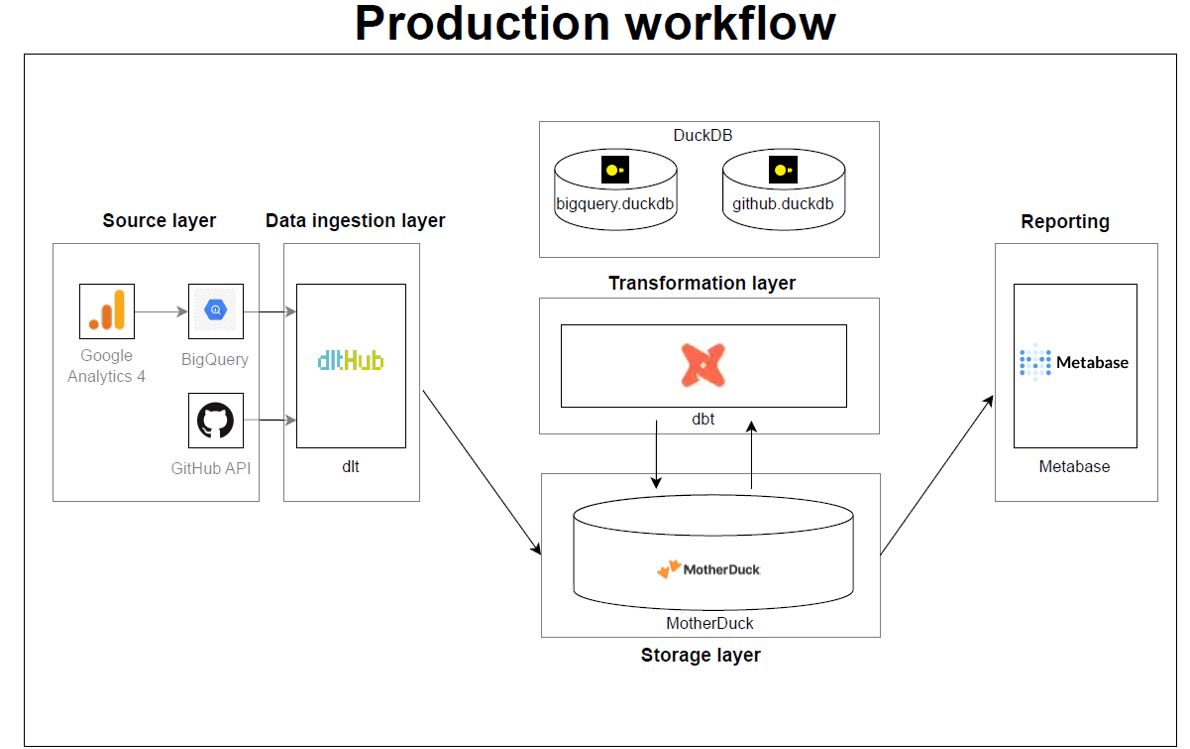
Thus I got a super simple and highly customizable MDS in a box that is also close to company production setting.
What does this MDS in a box version look like?
| Tool | Layer | Why it’s awesome |
|---|---|---|
dlt | data ingestion | ridiculously easy to write a customized pipeline in Python to load from any source |
| DuckDB | data warehouse in your laptop | free, fast OLAP database on your local laptop that you can explore using SQL or python |
| MotherDuck | data warehouse in the cloud | DuckDB, but in cloud: fast, OLAP database that you can connect to your local duckdb file and share it with the team in company production settings |
| dbt | data transformation | an amazing open source tool to package your data transformations, and it also combines well with dlt, DuckDB, and Motherduck |
| Metabase | reporting | open source, has support for DuckDB, and looks prettier than my Python notebook |
How this all works
The example that I chose was inspired by one of my existing workflows: that of understanding dlt-related metrics every month. Previously, I was using only Google BigQuery and Metabase to understand dlt’s product usage, but now I decided to test how a migration to DuckDB and MotherDuck would look like.
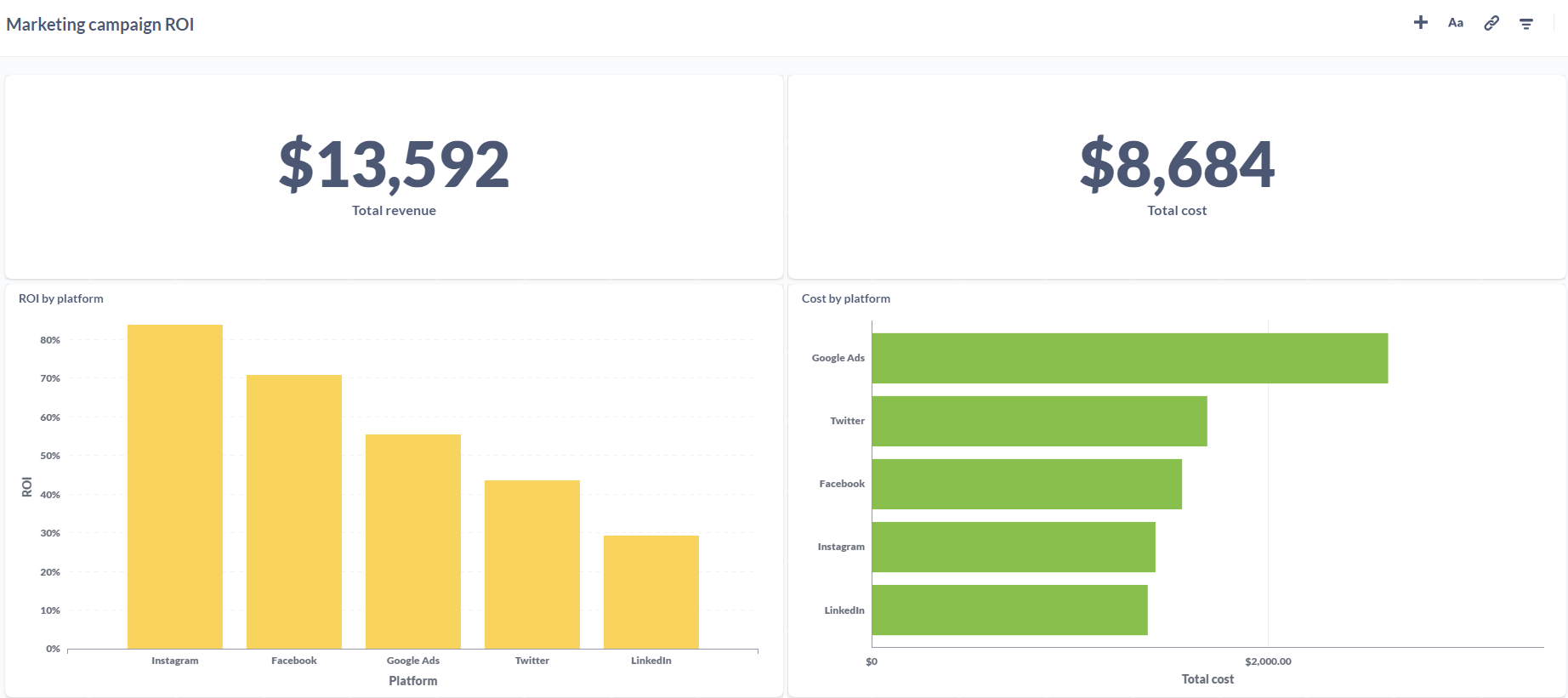
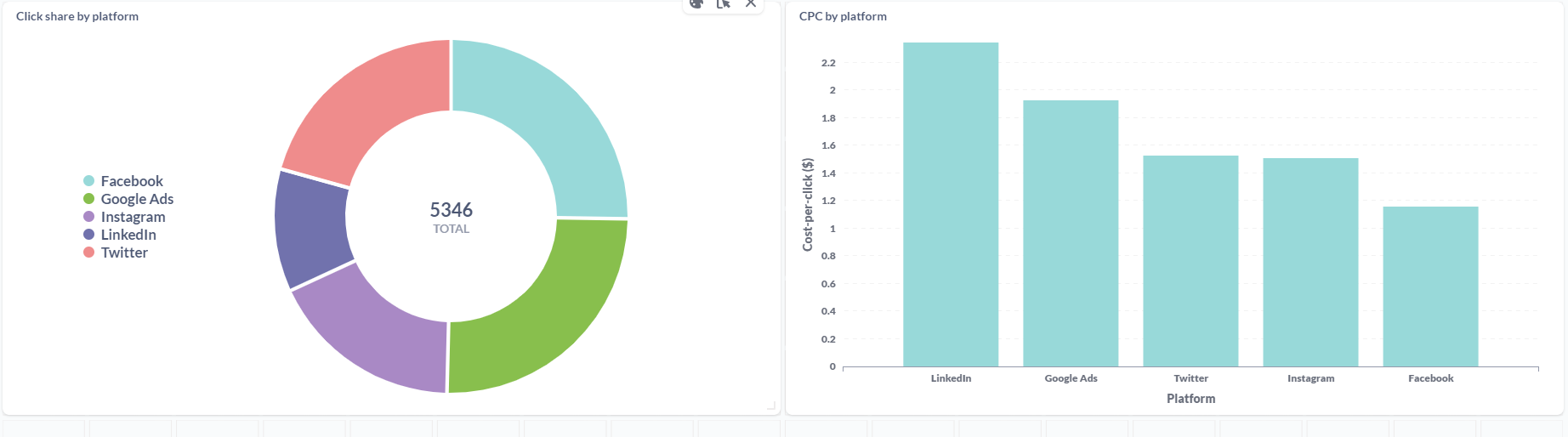
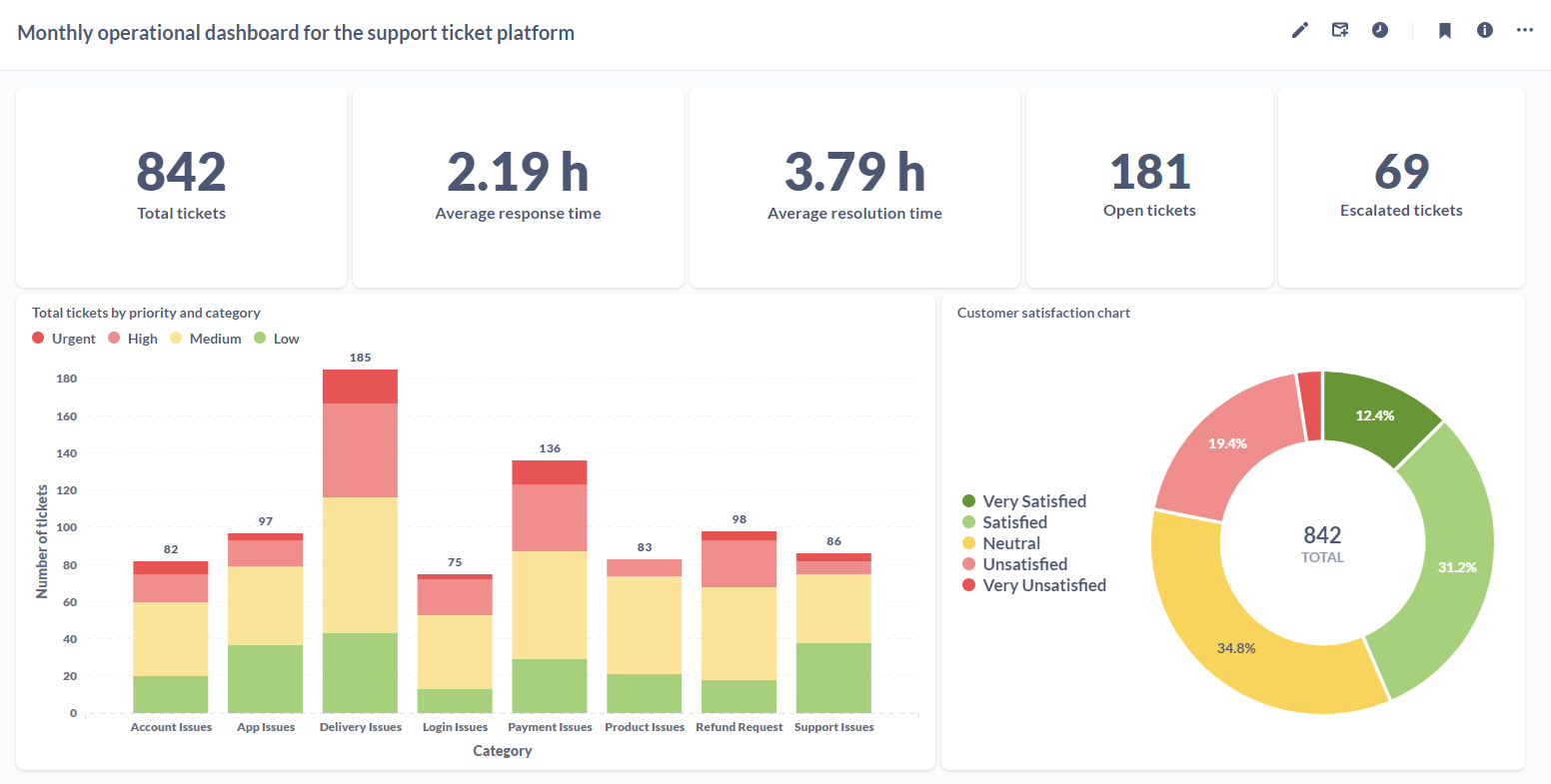
The idea is to build a dashboard to track metrics around how people are using and engaging with dlt on different platforms like GitHub (contributions, activity, stars etc.), dlt website and docs (number of website/docs visits etc.).
This is a perfect problem to test out my new super simple and highly customizable MDS in a box because it involves combining data from different sources (GitHub API, Google Analytics 4) and tracking them in a live analytics dashboard.
Loading the data using
dltThe advantage of using
dltfor data ingestion is thatdltmakes it very easy to create and customize data pipelines using just Python.In this example, I created two data pipelines:
- BigQuery → DuckDB:
Since all the Google Analytics 4 data is stored in BigQuery, I needed a pipeline that could load all events data from BigQuery into a local DuckDB instance. BigQuery does not exist as a verified source for
dlt, which means that I had to write this pipeline from scratch. - GitHub API → DuckDB:
dlthas an existing GitHub source that loads data around reactions, PRs, comments, and issues. To also load data on stargazers, I had to modify the existing source.
dlt is simple and highly customizable:
Even though Bigquery does not exist as a dlt source, dlt makes it simple to write a pipeline that uses Bigquery as a source. How this looks like:
Create a
dltproject:dlt init bigquery duckdbThis creates a folder with the directory structure
├── .dlt
│ ├── config.toml
│ └── secrets.toml
├── bigquery.py
└── requirements.txtAdd BigQuery credentials inside .dlt/secrets.toml.
Add a Python function inside bigquery.py that requests the data.
Load the data by simply running
python bigquery.py.See the accompanying repo for a detailed step-by-step on how this was done.
The data in BigQuery is nested, which dlt automatically normalizes on loading.
BigQuery might store data in nested structures which would need to be flattened before being loaded into the target database. This typically increases the challenge in writing data pipelines.
dltsimplifies this process by automatically normalizing such nested data on load.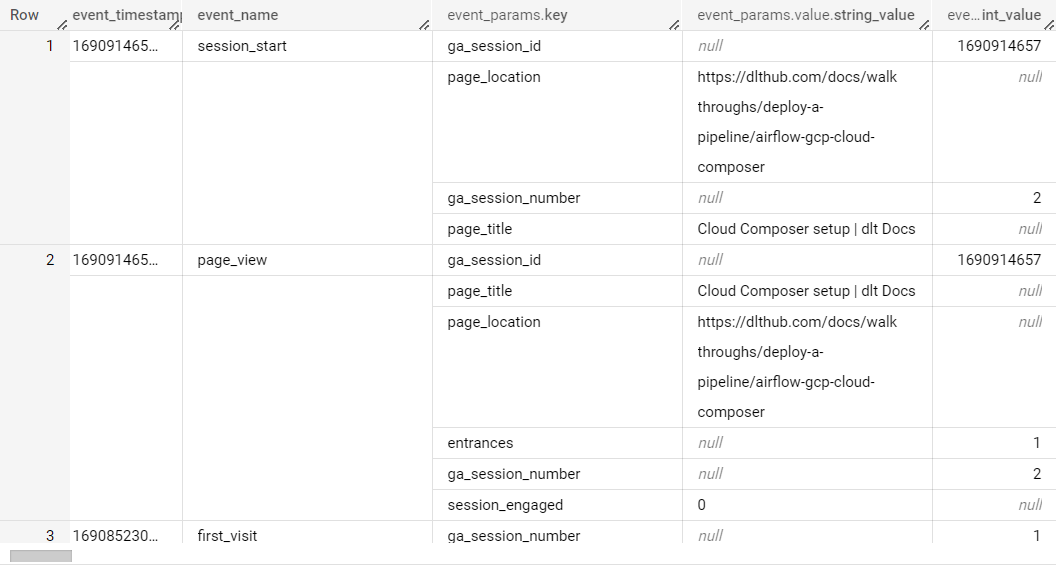
Example of what the nested data in BigQuery looks like.
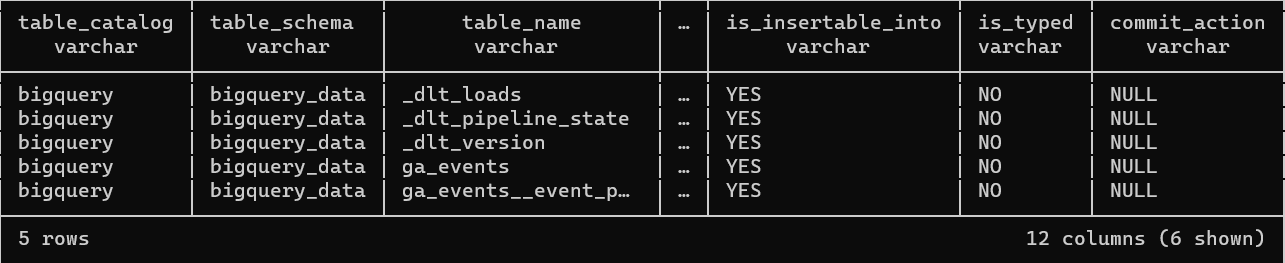
dltloads the main data into tablega_events, and creates another tablega_events__event_paramsfor the nested data.The existing Github source does not load information on stargazers. dlt makes it easy to customize the Github source for this.
The way the existing GitHub verified source is written, it only loads data on GitHub issues, reactions, comments, and pull requests. To configure it to also load data on stargazers, all I had to do was to add a python function for it in the pipeline script.
See the accompanying repo for a detailed step-by-step on how this was done.
- BigQuery → DuckDB:
Since all the Google Analytics 4 data is stored in BigQuery, I needed a pipeline that could load all events data from BigQuery into a local DuckDB instance. BigQuery does not exist as a verified source for
Using DuckDB as the data warehouse
DuckDB is open source, fast, and easy to use. It simplifies the process of validating the data after loading it with the data pipeline.In this example, after running the BigQuery pipeline, the data was loaded into a locally created DuckDB file called ‘bigquery.duckdb’, and this allowed me to use python to the explore the loaded data:
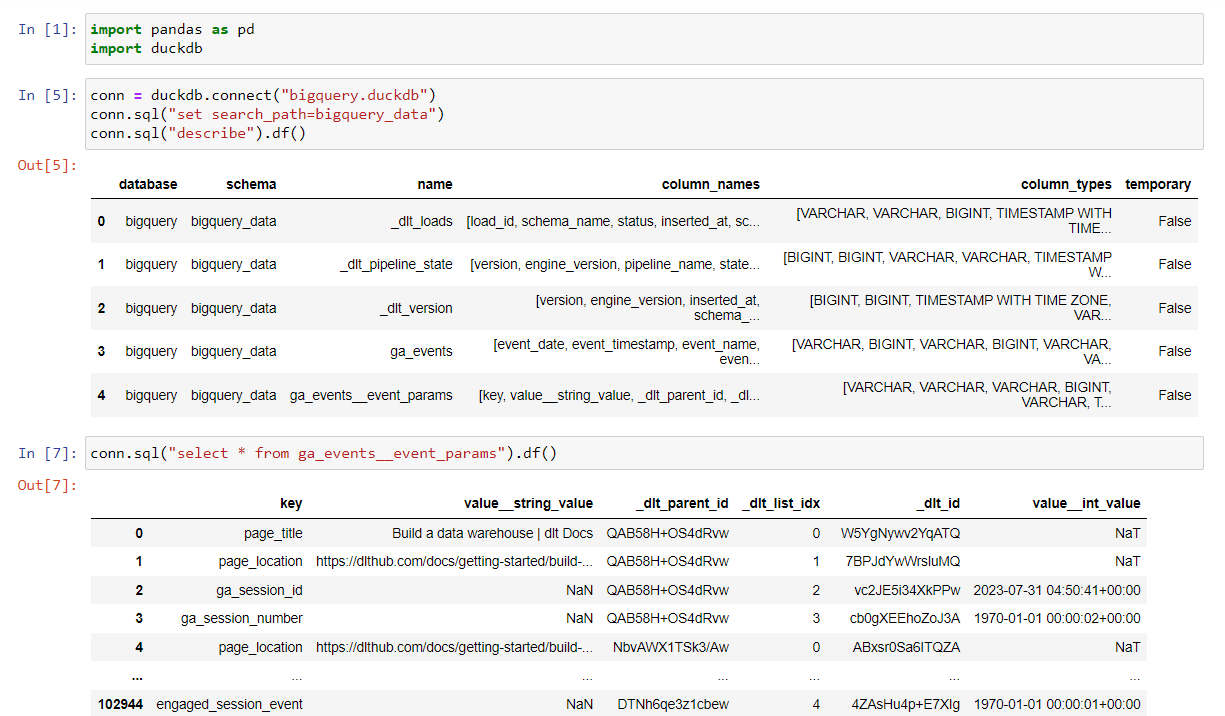
The best thing about using DuckDB is that it provides a local testing and development environment. This means that you can quickly and without any additional costs test and validate your workflow before deploying it to production.
Also, being open source, it benefits from community contributions, particularly dbt-duckdb adapter and the DuckDB Metabase driver, which make it very useful in workflows like these.
dbt for data transformations
Because of
dlt’s dbt runner and DuckDB’s dbt adapter, it was very easy to insert dbt into the existing workflow. What this looked like:- I first installed dbt along with the duckdb adapter using
pip install dbt-duckdb. - I then created a dbt project inside the dlt project using
dbt initand added any transforms as usual. - Finally, I added the
dlt’s dbt runner to my python script, and this configured my pipeline to automatically transform the data after loading it. See the documentation for more information on the dbt runner.
- I first installed dbt along with the duckdb adapter using
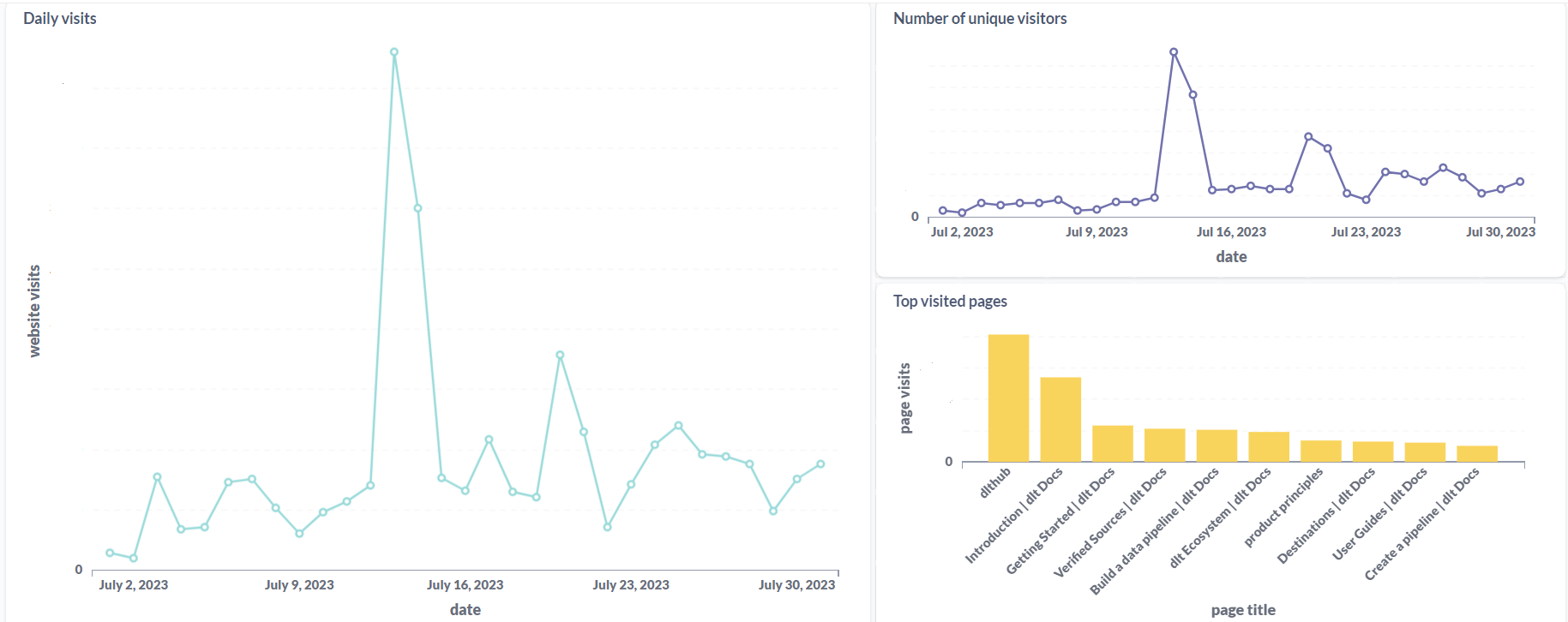
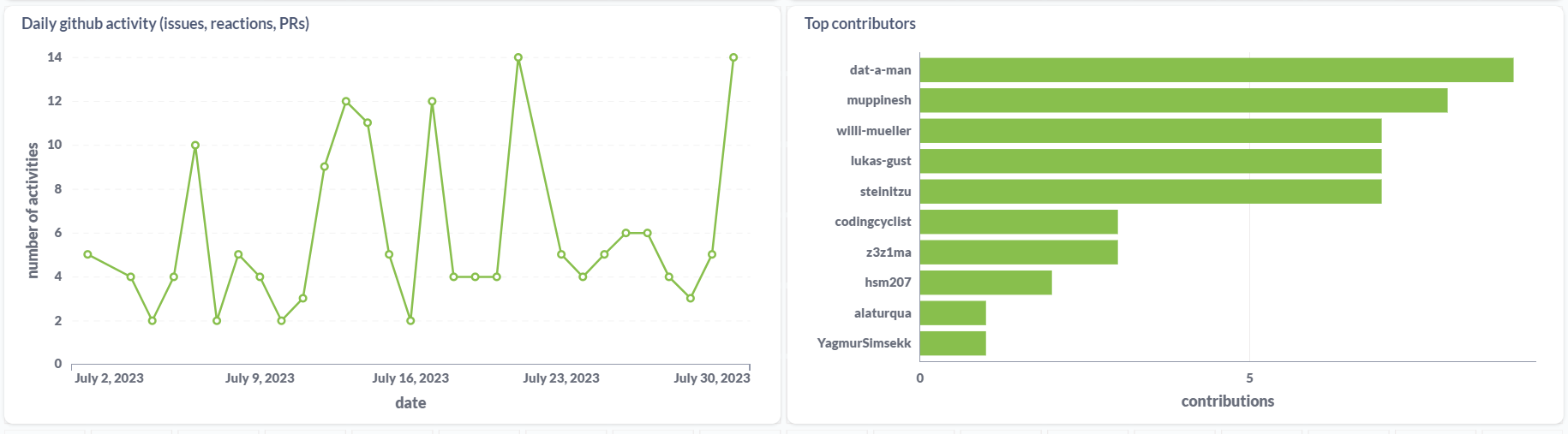
Metabase for the dashboard
Metabase OSS has a DuckDB driver, which meant that I could simply point it to the DuckDB files in my system and build a dashboard on top of this data.


Going to production: Using MotherDuck as the destination
So far the process had been simple. The integrations among
dlt, dbt, DuckDB, and Metabase made the loading, transformation, and visualization of data fairly straight-forward. But the data loaded into DuckDB existed only in my machine, and if I wanted share this data with my team, then I needed to move it to a different storage location accessible by them.The best and the easiest way to do this was to use MotherDuck: a serverless cloud analytics platform built on top of DuckDB, where you can host your local DuckDB databases.
Why choose MotherDuck
Go from development to production with almost no code re-writing:
This was my main reason for choosing MotherDuck. MotherDuck integrates with
dlt, dbt, and Metabase just as well as DuckDB. And I was able to replace DuckDB with MotherDuck in my pipeline with almost no code re-writing!What this process looked like:
- First, I modified the
dltpipelines to load to MotherDuck instead of DuckDB as follows:- I added credentials for MotherDuck inside
.dlt/secrets.toml - I made a minor update to the code: i.e. just by changing
destination = "duckdb"todestination = "motherduck"the pipelines were already configured to load the data into MotherDuck instead of DuckDB
- I added credentials for MotherDuck inside
- With this change, I was already able to deploy my pipelines with GitHub actions.
- After deploying, I simply changed the DuckDB path to the MotherDuck path in Metabase, and then I deployed Metabase on GCP.
The reason this is great is because it greatly simplifies the development lifecycle. Using DuckDB + MotherDuck, you can develop and test your pipeline locally and then move seamlessly to production.
- First, I modified the
Very easy to copy local DuckDB databases to MotherDuck
This was especially useful in this demo. Google Analytics 4 events data is typically large and when fetching this data from BigQuery, you are billed for the requests.
In this example, after I ran the BigQuery -> DuckDB pipeline during development, I wanted to avoid loading the same data again when deploying the pipeline. I was able to do this by copying the complete local DuckDB database to MotherDuck, and configuring the pipeline to only load new data from BigQuery.
Easy to share and collaborate
Being able to share data with the team was the main goal behind moving from DuckDB to a cloud data warehouse. MotherDuck provides a centralized storage system for the DuckDB databases which you can share with your team, allowing them to access this data from their own local DuckDB databases.
In my example, after I load the data to MotherDuck, I can provide access to my team just by clicking on ‘Share’ in the menu of their web UI.
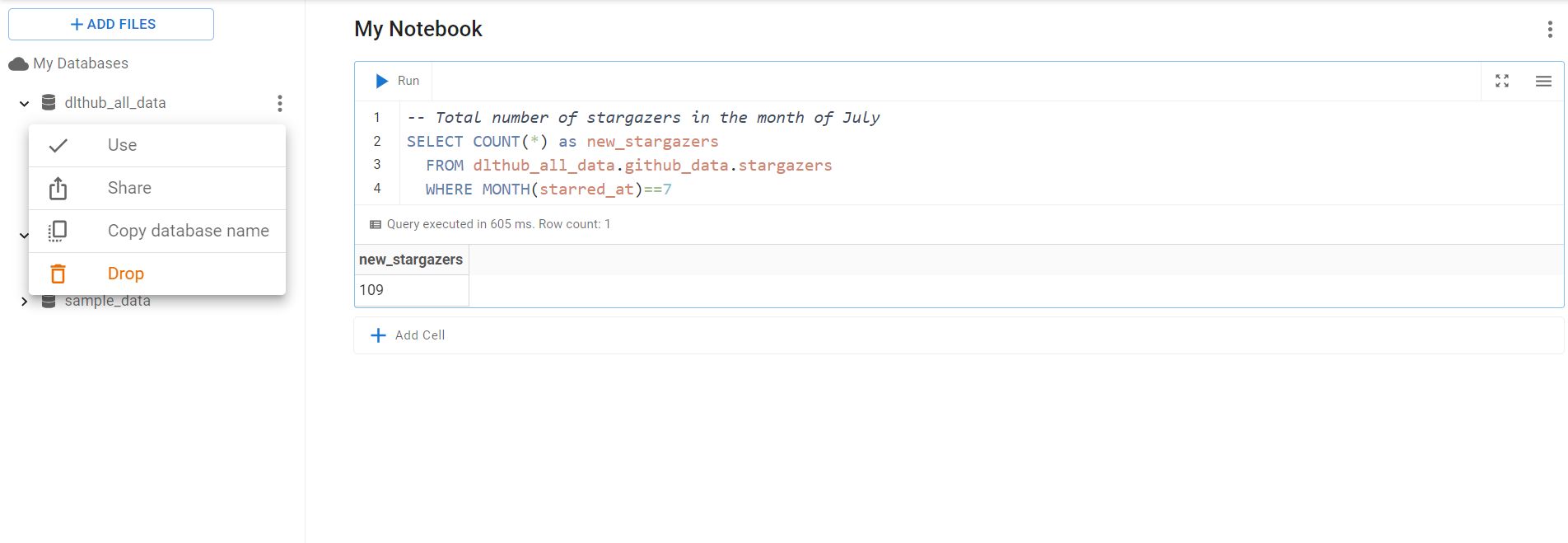
Conclusion:
This was a fun and interesting exercise of creating a simple, yet powerful Modern Data Stack in a box. For me the biggest positives about this approach are:
- Everything was happening on my laptop during the development giving me full control. Still going to production was seamless and I didn't need to change my code and data transformations at all.
- I really liked that I could come with my ideas on what data I need and just write the pipelines in Python using
dlt. I was not forced to pick from a small pull of existing data extractors. Both, customizing code contributed by others and writing my bigquery source from scratch, were fun and not going beyond Python and data engineering knowledge that I had. - I'm impressed by how simple and customizable my version of MDS is.
dlt, DuckDB, and MotherDuck share similar philosophy of giving full power to the local user and and making it easy to interact with them in Python.
I repeat this entire process for the BigQuery pipeline in this video:
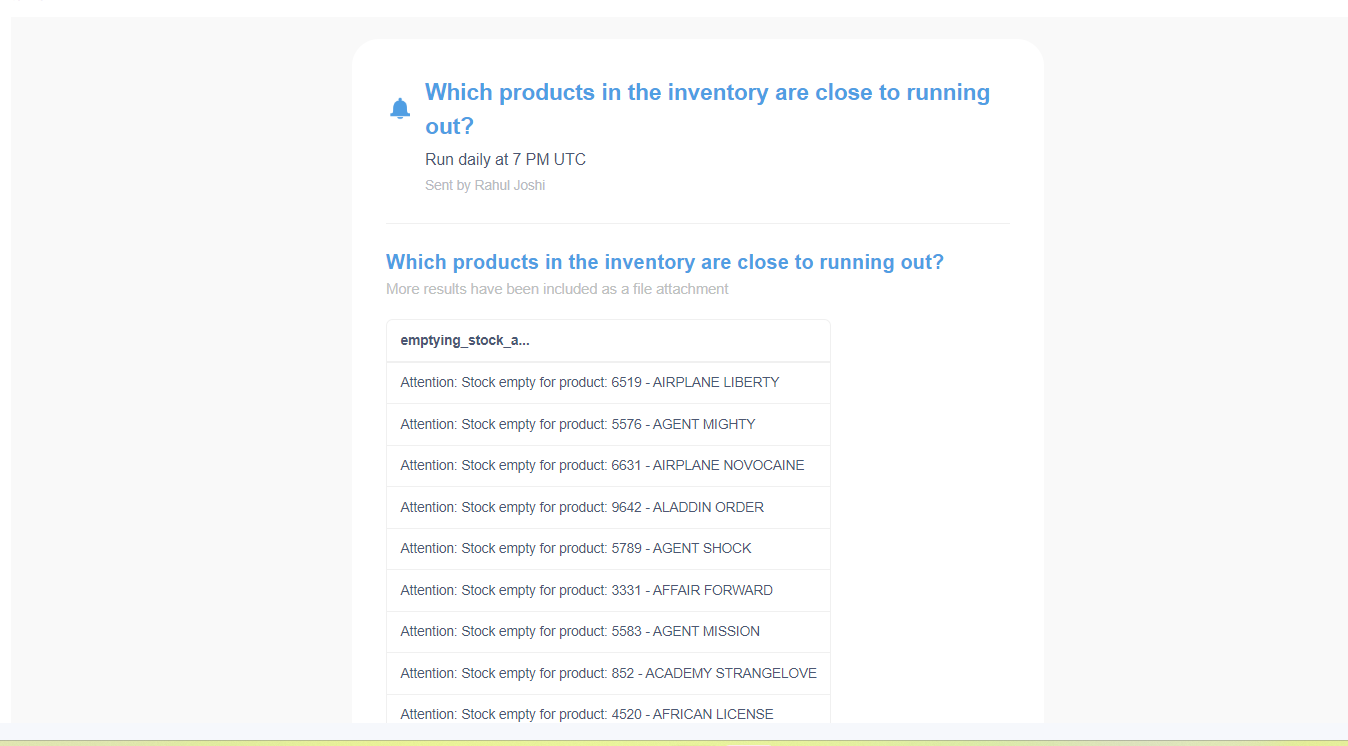
 In addition to this, we were also able to set up email alerts to get notified whenever the stock of a DVD was either empty or close to emptying.
In addition to this, we were also able to set up email alerts to get notified whenever the stock of a DVD was either empty or close to emptying.